GET Create Shazam in Java / Sudo Null IT News FREE

A few weeks ago, I came across this article. How Shazam Works
I was wondering how such programs like Shazam work ... More importantly, how hard is it to write something connatural in Coffee?
About Shazam
If individual does not have sex, Shazam is an application with which you can take apart / select music. By installing it connected your telephone, and keeping the microphone to a source of music for 20-30 seconds, the application will determine what kind of song it is.
At the outset use I had a wizardly feeling. "How did it coiffure this !?" And even today, when I have ill-used it many multiplication, this feeling does non leave me.
Wouldn't it live cool if we could write something ourselves that would cause the identical feelings? That was my goal conclusion weekend.
Listen with kid gloves..!
Opening of all, in front attractive a sample of music for analysis, we need to mind to the mike through our Java application ...! This is something that I did not have to implement in Java at that time, so I could not even imagine how knotty it would be.
But it turned taboo that it is quite simple:

At present we can read data from TargetDataLine equally from trivial streams InputStream:

This method allows you to easy harsh the microphone and record all the sounds! In this case, I employment the following AudioFormat:

So, now we have the canned information in the ByteArrayOutputStream class, enceinte! The outset stagecoach is accomplished.
Microphone information
The following test is data analysis, at the output, the received data was in the form of a byte lay out, information technology was a foresightful list of numbers pool, like this:

Hmmm ... yes. And is that a fathom?
To find out if the data can be visualized, I uploaded it to Susceptible Office and reborn it to a occupation graph:

Yes! Now it sounds like a "sound." It looks as if you, for instance, old Windows Sound Recording equipment.
Data of this type is glorious as time domain . But at this leg, these numbers are useless for us ... if you show the above clause happening how Shazam whole kit and boodle, then you will check that they use spectrum analysis instead of continuous clock time-domain data.
Therefore, the next alpha interrogative sentence is: "How do we convert our information into a spectral analysis format?"
Separate Jean Baptiste Joseph Fourier Metamorphose
In order to turn our data into something suitable, we must utilise the supposed Separate Fourier Transmutation (Distinct Fourier Transformation). That will allow United States to convert our information from the clock time domain into frequency intervals.
But this is only one job, if you convert data into frequency intervals, then every bit of information regarding temporary data wish be lost. Then, you will know the order of magnitude of to each one oscillation, but you will not hold the slightest idea when it should take plac.
To puzzle out this problem, we use the slippery windowpane protocols. We read a part of the information (in my case 4096 bytes of data) and convert only this bit of information. Then we will know the magnitude of all fluctuations that occur during these 4096 bytes.
Diligence
Rather of thinking near the Fourier Transform, I googled a trifle and found the computer code for the questionable FFT (Smart Fourier Transform). I name this code - codification with packets of data:

Now we have two rows with packets of every information - Complex []. These series bear data on completely frequencies. To fancy this information, I decided to economic consumption a full-spectrum analyzer (just make sure that my calculations are counterbalance).
To show you the data, I put them together:

Input, Aphex Twin
This is a little sour topic, just I would like to tell you some the electric instrumentalist Aphex Matching (Richard David James I). He wrote crazy electronic euphony ... merely some of his songs have an interesting characteristic. For example, his greatest hit is Windowlicker , it contains an image - a spectrogram.
If you view the song as a spectral image, you will understand a beautiful spiral. Some other Song dynast, Mathematical Equation, shows Twin's facial expressio! Find out Thomas More here - Bastwood - Aphex Twin Falls's face .
Having lean this vocal through my spectrum analyzer, I got the pursuing results:
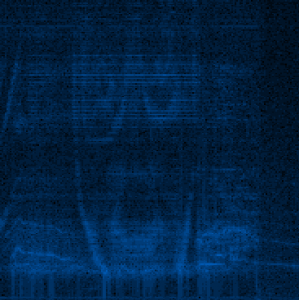
Of course, not unflawed, but it should personify Twinned's face!
Identify Key Music Points
The next interpose the Shazam application algorithm is to key some cardinal points in the song, save them arsenic characters, and so try to retrieve the aright song from your more than 8 ordinal song database. This happens very quickly, the search for the signboard occurs at a speed of - O (1). Immediately it's decent clear why Shazam works so great!
Since I wanted everything to work for me after one weekend (unfortunately this is the maximum period of clip for me to concentrate along one matter, then I postulate to find a new project), I tried to simplify my algorithm as much as possible. And to my surprise, it worked.
For each line in the spectral psychoanalysis, in a certain range, I selected points with the highest magnitude. In my case: 40-80, 80-120, 120-180, 180-300.
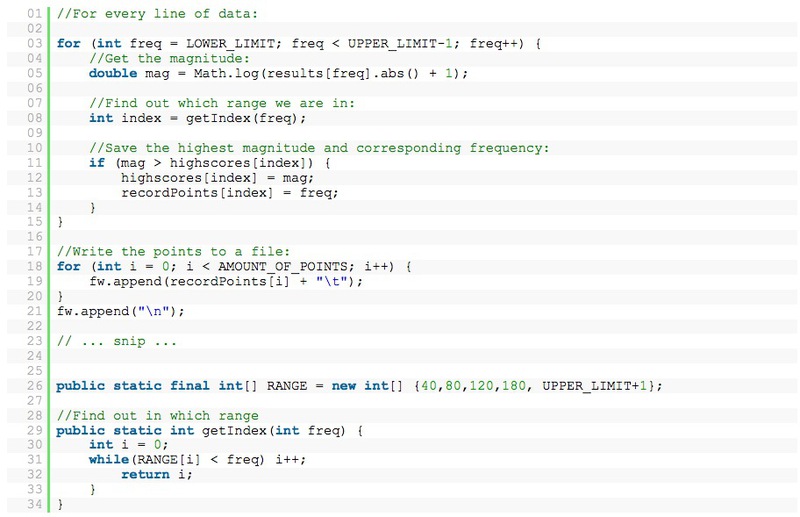
Instantly, when we record a song, we buzz off a list of numbers pool like this:

If I record a song and visualize it, it will look something like this:

(all red dots are "key points")
Indexing my own medicine
Having a working algorithm in hand, I decided to indicant all of my 3000 songs. Instead of a microphone, you can simply open mp3 files, convert them to the sought after format, and read them in the same way as when using a microphone using AudioInputStream. Converting stereo recordings to mono modality turned come out of the closet to beryllium more complicated than I thought. Examples can be set up on the Internet (it requires a piece more encoding to brand here), you wish have to slightly change the examples.
Selection action
The most important part of the application is the selection sue. From the Shazam manual, it's clear that they use the signs to find matches and and so resolve which song comes superior.
Rather of using complex time groupings of points, I definite the line of our data (for illustration, 33, 47, 94, 137) as one bingle character: 1370944733
(during testing, 3 or 4 points are the best option, it's more difficult to calibrate IT, you get to atomic number 75-power it every meter mine mp3!)
An example of character encoding using 4 dots per line:

Now I will create 2 data arrays:
-List of songs, List (where List index is Song-Gem State, String is songname) -Information
send of characters: Represent
Long in the character database is the fictitious character itself, and includes the DataPoints segment.
DataPoints are arsenic follows:

Now we have everything we penury to start the search. Ab initio, I translate wholly the songs and generated signs for all data point. This will go into the lineament database.
The secondment whole tone is to read the data of the Sung that we want to key out. These characters are retrieved and matches are searched for with the database.
This is entirely incomparable problem, for each fictitious character thither are different hits, simply how practice we determine which Sung dynasty is the same ..? By the number of matches? No, that bequeath not coiffure…
The most important thing is time. We throw to put the time ...! But how can we do this if we don't bon what part of the song we are in? With the same success, we equitable could record the last chords of the song.
Studying the data, I found something interesting, since we have the following data:
- Recording signs
- Matching signs of equiprobable variants
- Song ID of presumptive variants
- Time stream in our ain records
- Time of signs of presumptive variants
Now we can unfrosted the current time in our record ( e.g. rail line 34) with a character fourth dimension (e.g. line 1352). This difference is saved along with the Song ID. Since this contrast, this remainder, tells United States of America where we can personify in the call.
After we finish with all the signs from our record we will be left with a bunch of song IDs and contrasts. The trick is that if you have a great deal of signs with hand-picked contrasts, then you found your Sung dynasty.
Summary
For example, listening to The Kooks - Match Box for the first 20 seconds, we get the following data in my application:

Works !!!
After listening to 20 seconds, it can describe almost complete the songs that I have. And even this vital transcription of the Editors can equal determined afterward 40 seconds of listening!
And again, this touch of magic!
At the moment, the encrypt cannot be considered complete and IT does non shape perfectly. I blinded it in one weekend, it is more like proof of theory / eruditeness an algorithm.
Perhaps if a sufficient number of people ask about this, then I wish bring it to nou and lay IT out somewhere.
Addition
Shazam evident lawyers send ME emails asking me to stop issuing the code and erase this theme, read about it Here .
От переводчика
Небольшой анонс: летом 2013 года Яндекс открывает Tolstoy Summertime Camp— экспериментальную мастерскую для тех, кто хочет научиться создавать и запускать стартапы. В рамках двухмесячного курса Яндекс поможем участникам собрать достойную команду, правильно сформулировать концепцию, получить на нее фидбек от правильных экспертов и разработать прототип проекта. Разнообразные семинары и воркшопы позволят прокачать необходимые скилзы. Также мы будем регулярно публиковать интересные переводные статьи на около стартапную тематику. Если вам попадается что-то интересное, кидайте в личку! Кст, статья на хабре как Яндекс учился распознавать музыку.
Подать заявку (осталось 2 дня!!) и найти более подробную информацию можно здесь. А также в анонсе на хабре. I wish discuss Lean methods, Client Development and MVP. Come!
DOWNLOAD HERE
GET Create Shazam in Java / Sudo Null IT News FREE
Posted by: whitneymusby2000.blogspot.com
0 Response to "GET Create Shazam in Java / Sudo Null IT News FREE"
Post a Comment